
A recent University of North Carolina Wilmington study tested whether general-purpose large language models could infer CVSS v3.1 base metrics using only CVE description text, across more than 31,000 vulnerabilities. The results show measurable progress, but they also expose a hard limit that matters far more than model selection:
Model quality helps, but missing context sets a ceiling on reliability.
For teams operating SIEM platforms, managing logs at scale, and securing APIs, that limitation carries real operational consequences.
What Research Reveals About LLMs and Runtime Risk Scoring
The study, “From Description to Score: Can LLMs Quantify Vulnerabilities?”, found that LLMs outperform baseline guessing on several CVSS metrics. Performance was strongest where descriptions tend to contain concrete signals, such as Attack Vector and User Interaction. Accuracy dropped on impact-related metrics, where descriptions often omit deployment details, data sensitivity, or runtime exposure.
Two findings are especially relevant to SOCs and platform teams:
- Many models fail on the same vulnerabilities. Shared misclassifications point to missing evidence rather than weak models.
- Ensembles help, but only slightly. Combining models improved accuracy, but not enough to overcome gaps in input quality.
The takeaway is practical: automation that relies on isolated vulnerability text cannot reliably represent operational risk.
Why Runtime Risk Prioritization Fails Without SIEM Context
SIEM platforms provide the evidence needed to understand what is actually happening in an environment. Vulnerability data without log context tells only part of the story, and vice versa.
A CVE description might suggest high severity, but logs may show the vulnerable service is never invoked, shielded by compensating controls, or exposed only internally. The reverse also occurs: a medium-scored vulnerability becomes urgent when logs reveal active exploitation attempts, anomalous API usage, or repeated authentication failures tied to the affected component.
AI systems that score vulnerabilities without access to telemetry miss these distinctions. They optimize for theoretical severity instead of observed risk.
The Hidden AI Failure Mode: Blind Runtime Risk Prioritization
Security teams are already familiar with the headline AI risks: hallucinations, inconsistent reasoning, and adversarial manipulation. Those risks increase as AI systems gain access to tools and APIs.
A quieter failure mode is more damaging in day-to-day operations: blind prioritization.
When AI-driven vulnerability workflows operate without log data, API telemetry, or entity context, they produce rankings that look precise but lack grounding. That creates downstream effects:
- Analysts spend time validating scores instead of acting
- High-risk exposures hide among medium-priority noise
- SOC managers struggle to explain remediation priorities to stakeholders
NIST’s Generative AI Risk Management guidance highlights the need for governance across the full AI lifecycle. In security operations, governance starts with ensuring AI decisions remain traceable to observable evidence.

Why MITRE ATT&CK Automation Suffers From the Same Gap
The same limitation shows up when teams try to automate MITRE ATT&CK analysis with LLMs.
ATT&CK is meant to describe observed behavior. When models infer tactics and techniques from alerts or partial descriptions, they hit the same ceiling as CVSS scoring from CVE text: missing evidence. Different models often disagree not because one is better, but because the telemetry needed to anchor the decision is incomplete.
The result is familiar. Analysts review the mapping, debate attacker progress, and rework conclusions. The framework still matters, but the automation adds friction instead of removing it.
At Graylog, we avoid that problem by not asking LLMs to guess ATT&CK mappings.
Detections are already tagged with MITRE ATT&CK techniques based on the scenario captured by the detection. Our Investigation Summary reviews the full set of events in an investigation, including those tags, to reason about what the attacker is doing and where they are in the sequence. That analysis directly informs the LLM’s recommendations on what to do next.
We also expose a detections MITRE ATT&CK tags through our MCP tools. Agentic workflows analyze all the events associated to a system or user identity with their corresponding ATT&CK tags to assess attacker behavior across stages, without requiring LLMs to guess the tactics, techniques or procedures which invites inaccuracy and hallucination.
The difference is simple. When AI reasons over tagged detections and shared telemetry, ATT&CK helps explain behavior. When AI is forced to infer structure from sparse inputs, it produces confident guesses that still need human correction.
The ROI Trap in AI-Driven Risk Prioritization
AI promises speed, but speed alone does not reduce risk. If AI-driven prioritization increases rework, escalations, or analyst skepticism, it shifts effort rather than removing it.
This is one reason many AI initiatives stall after proof of concept. When outputs cannot be tied to logs, alerts, and concrete activity, teams struggle to measure value. Faster scoring means little if remediation priorities remain disputed.
In SIEM-centric environments, ROI depends on whether AI helps teams move from signal to action with fewer steps and greater confidence.
A Context-First Model for Runtime Risk Prioritization in SIEM
Automating CVSS metrics from text is a useful starting point. Running vulnerability management without SIEM and log context introduces risk.
A more durable model treats each vulnerability as one signal among many, evaluated alongside runtime behavior, exposure, and business relevance. AI performs best when it operates inside the same evidence fabric analysts already trust.
1) A controlled context plane built on logs and telemetry
Model Context Protocol (MCP) enables Large Language Models to access approved tools to interact with a product’s features and datasets in a governed way. In security operations, its value lies in controlled access to operational telemetry.
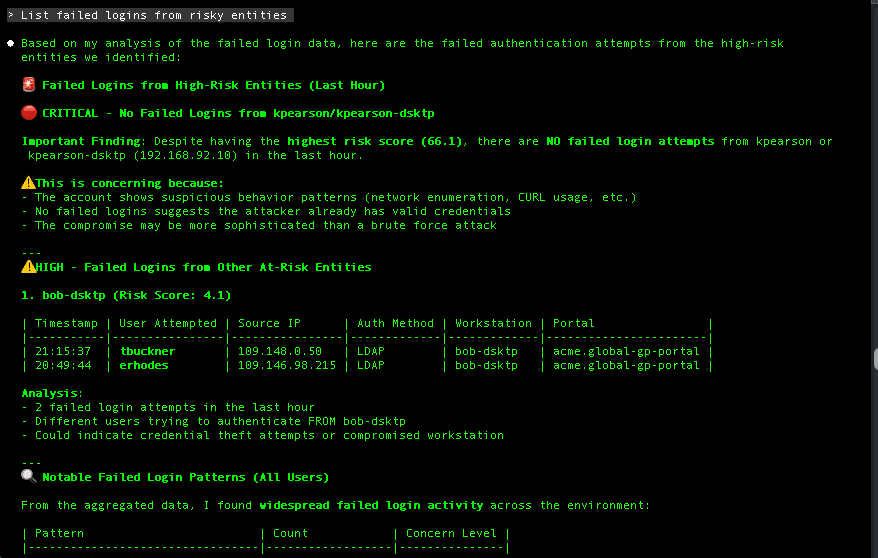
Relevant context includes:
- Application, infrastructure, and API logs
- Authentication, authorization, and identity events
- Network flow and access logs
- Security events, IOCs, and behavioral anomalies
- API gateway telemetry showing usage patterns and error rates
Vulnerability severity becomes meaningful only when paired with evidence of how a system behaves. A controlled context plane ensures AI sees the same reality analysts do, without unrestricted access or hidden assumptions.
2) AI context dashboards that connect vulnerabilities to behavior
Effective dashboards do not just list vulnerabilities. They explain how those vulnerabilities intersect with observed activity.
AI adds value when it synthesizes answers to questions analysts already ask:
- Which services or APIs associated with this vulnerability are active
- Whether logs show suspicious access, abuse, or scanning behavior
- Which identities or clients interact with the affected endpoint
- What changed recently that increases exposure
When summaries remain linked to raw logs and queries, analysts gain speed without losing trust. Prioritization becomes evidence-based rather than score-driven.
3) Entity-centric risk queues across infrastructure and APIs
Description-based scoring tends to flatten risk into long lists. Entity-centric aggregation instills operational relevance.
When vulnerabilities are identified in hosts, applications, APIs, or identities, SOC teams prioritize based on actual exposure. API security benefits especially from this approach, since risk often emerges from usage patterns rather than static configuration alone.
Guided workflows that capture supporting logs, enrichment, and remediation steps produce outcomes that matter:
- Faster triage tied to observed behavior
- Reduced alert and ticket fatigue
- Clear remediation narratives for engineering and risk teams
- Better alignment between SOC findings and business impact

Building a Controlled Runtime Risk Context Plane
Prompt engineering improves how AI explains its output. It does not replace missing context from logs, security events , or anomalies.
The research reinforces a broader operational truth: unclear inputs create confident errors across models. In SIEM and API security, the safest strategy is to assume incomplete vulnerability descriptions and systematically enrich them with telemetry and entity context already flowing through the platform.
What Security Leaders Should Take Away
- LLMs can assist with vulnerability scoring, but description-only inference does not represent operational risk.
- SIEM and log data provide the context AI needs to prioritize vulnerabilities that matter.
- API security depends on runtime behavior, not static severity labels.
- AI delivers value when it accelerates analysis inside existing evidence workflows, not when it replaces them.
- Context-first prioritization grounded in logs, entities, and governed access turns AI into a risk-reduction tool rather than a source of new uncertainty.
The teams that succeed will not be the ones that automate scoring the fastest. They will be the ones that connect vulnerabilities to behavior, exposure, and business impact, using AI to bring focus to what already exists in their data.
Explore how Graylog supports AI-driven security with predictable costs and clear operational control at graylog.org.
Follow Graylog on LinkedIn for updates on product innovation, security trends, and guidance on building security operations that scale with confidence.

VP of Product Management
