
Everyone loves managed services until the bill comes in. High performance search indexers are a premium technology and have premium resource requirements. Graylog 6.0 introduces Data Tiering to put the management back in centralized data management.
Data tiering is a strategic approach to managing and storing large volumes of data by categorizing it into different levels. Separating data based on how frequently it’s accessed and the resources required to consume it. Graylog refers to these tiers as Hot, Warm, and Cold. This concept is crucial for IT Administrators and Security Professionals who often require data with immediate alerting capabilities and long-term retention for regulatory or compliance reasons. The choices for data management up until now have been either an observability platform requiring heavy resources to operate or an archive method outside of the platform entirely. Data Tiering introduces a middle tier, and combines both human management layers to reduce efforts for the high-performance searches and introduces a backend platform to manage all 3 layers.
Why Data Tiering Matters:
-
Improved Performance: Storing frequently accessed data on high-performance storage ensures quick access and processing, essential for real-time decision-making and threat response in security operations.
-
Resource Optimization: Data tiering allows for the efficient use of storage resources and reducing costs. The most resources go to the immediate requirements and can be scaled back as needed across the other tiers.
-
Scalability: As data volume grows, tiering provides a scalable way to manage storage, ensuring that expanding data does not overwhelm resources or degrade system performance.
-
Compliance and Retention: Tiering supports compliance with data retention policies by allowing less frequently accessed data to be moved to simpler, resource-efficient storage mechanisms, yet keeping it accessible for compliance checks or historical analysis.
Relevance to IT and Security:
-
Budget Control: By optimizing storage and compute resources, data tiering directly impacts the bottom line, allowing for better budget management without compromising on data availability or security posture.
-
Operational Efficiency: Administrators can ensure that critical security logs and operational data are readily accessible for analysis and response, while less critical data is stored more economically, yet still accessible when needed.
-
Strategic Data Management: Enables IT and security teams to strategically manage data lifecycle, from high-availability requirements for recent data to long-term storage for compliance and historical analysis.
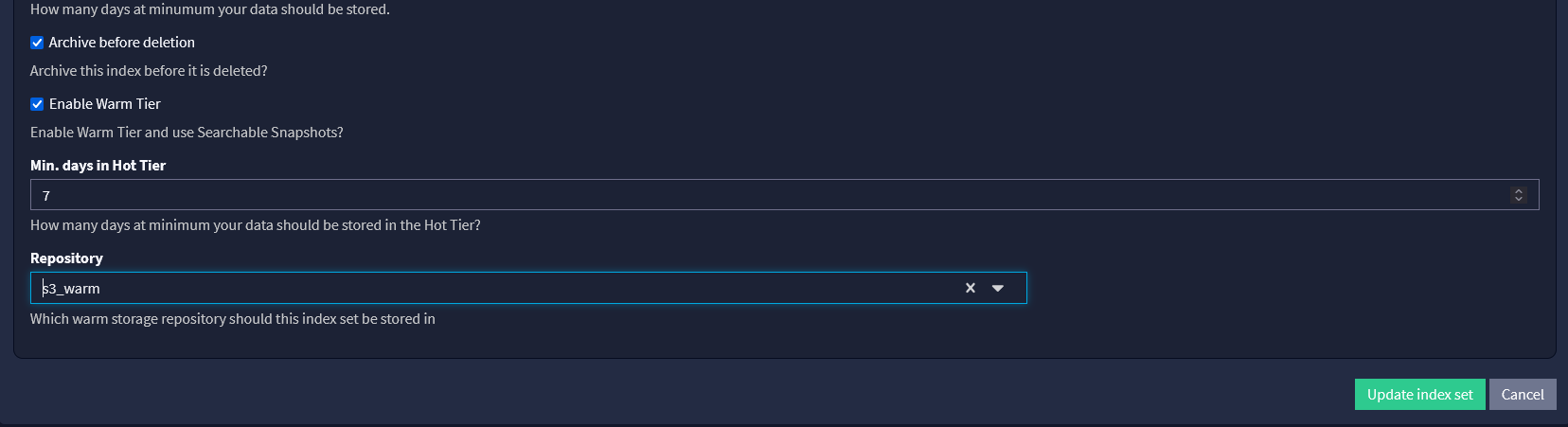
Technical Requirements
In order to take advantage of this, you will need an Enterprise or Security edition of Graylog 6.0 and Opensearch > v2.12 with searchable snapshots configured. Safeguarding your existing data integrity while making major changes to how its stored is something every data steward takes seriously.
Reach out to your Customer Success Manager to discuss options to leverage our expertise and maximize your data intelligence capabilities while greatly reducing TCO and overall risk.


Wrapping up
In summary, data tiering is not just a technical storage solution; it’s a strategic approach that supports operational efficiency, resource optimization, and strategic budgeting. Data tiering in Graylog empowers IT and Security Professionals to make informed decisions about the future of their data management, ensure critical data is always at their fingertips, and optimize the annual growth of centralized data across the organization.
