
Parsers make it easier to dig deep into your data to get every byte of useful information you need to support the business. They tell Graylog how to decode the log messages that come in from a source, which is anything in your infrastructure that generates log messages (e.g., a router, switch, web firewall, security device, Linux server, windows server, an application, telephone system and so on). Graylog collects all the raw log data from these sources, and the parsers turn it into structured data for storage, search, and analysis.
Graylog offers different parsers that you can use depending on your needs. One of those is the Key Value Parser. This parser allows you to parse the structured data into discrete fields so that you can search through it faster and more efficiently.
The Key Value Parser
The Key Value Parser looks for and returns information based on pairs of objects. The pairs are grouped by key and value. In a key value pair, there is a key on the left side, a value on the right side, and a key value delimiter (in this case =) in between them. There is also a delimiter between key value pairs to show where one pair ends and the next begins. (in this case it is a pipe character | ). The relationship between the two is as follows: The key is the name of the field (e.g., host name) and the value is what goes into the field (e.g., what you want to know about that key ).
Now that we have defined what a key value parser is and what it does, let’s take a look at an example of where the Key Value Parser adds value by getting you the data you need fast.
Let’s Take a Look
A router sends in a large block of text but you only care about specific pieces of information. This could be the source address, destination address, and/or host name. Maybe it’s an application that sends in the large block of text and you’re only interested in 20 specific fields. Regardless of the device sending in the logs, when you get that block of text you need an efficient method to break it up. This is where the Key Value Parser comes in.
Taking this a level deeper, say your network environment has 10,000 different Cisco devices of various models and code revisions. You want to monitor the same data for each of these devices. You are interested in monitoring message size for data exfiltration and message delivery failure. You also want to know about latency.
The text below is an example of a Key Value Separator set up for monitoring for the above data plus a few other interesting bits of information.
In this example, there are 10 key value pairs in the example. The first pair in the example is in bold in order to show the key and the value. The key in this example is datetime. The value we are seeking is the text after the equals sign up to the separator (pipe).
datetime=2019-09-10T12:36:21-0400 |aCode=HJ6y1e08MXakq5tZpM5L6Q |acc=CUSA118A37 |Delivered=true |IP=10.41.14.36|AttCnt=1|Dir=Inbound|ReceiptAck=250 2.6.0 <3daf9f36-3f9b-4509-93e0-3b4b0f6f2538@newvoicemessage> [InternalId=20779051785250, Hostname=SN608B4861.narf08.prod.outlook.com]. 161990 bytes in 0.200, 790.718 KB/sec Queued mail for delivery|MsgId=3daf9f3-f9b-4509-93e0-3b4b0f6f2538@newVoiceMessage. |Subject=New Voice Message from ACME, Inc. (702) 123-4567 on 09/10/2019 12:35 PM|Latency=30724|Sender=notify@ringcentral.com|Rcpt=yr055m@acme.com|Rcpt=yr055m@acme.com |AttSize=101709|Attempt=1|TlsVer=TLSv1.2|Cphr=TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA384|Snt=150346|UseTls=Yes|Route=Inbound IP</3daf9f36-3f9b-4509-93e0-3b4b0f6f2538@newvoicemessage>
The Key Value Parser allows Graylog to turn the text above into the nicely formatted example below, making it much easier for you to search for the specific data you’re monitoring. Parsing data into individual fields allows users to create visualizations, like charts, tables, maps etc. It also enables alerting and reporting, based on the content of those fields.
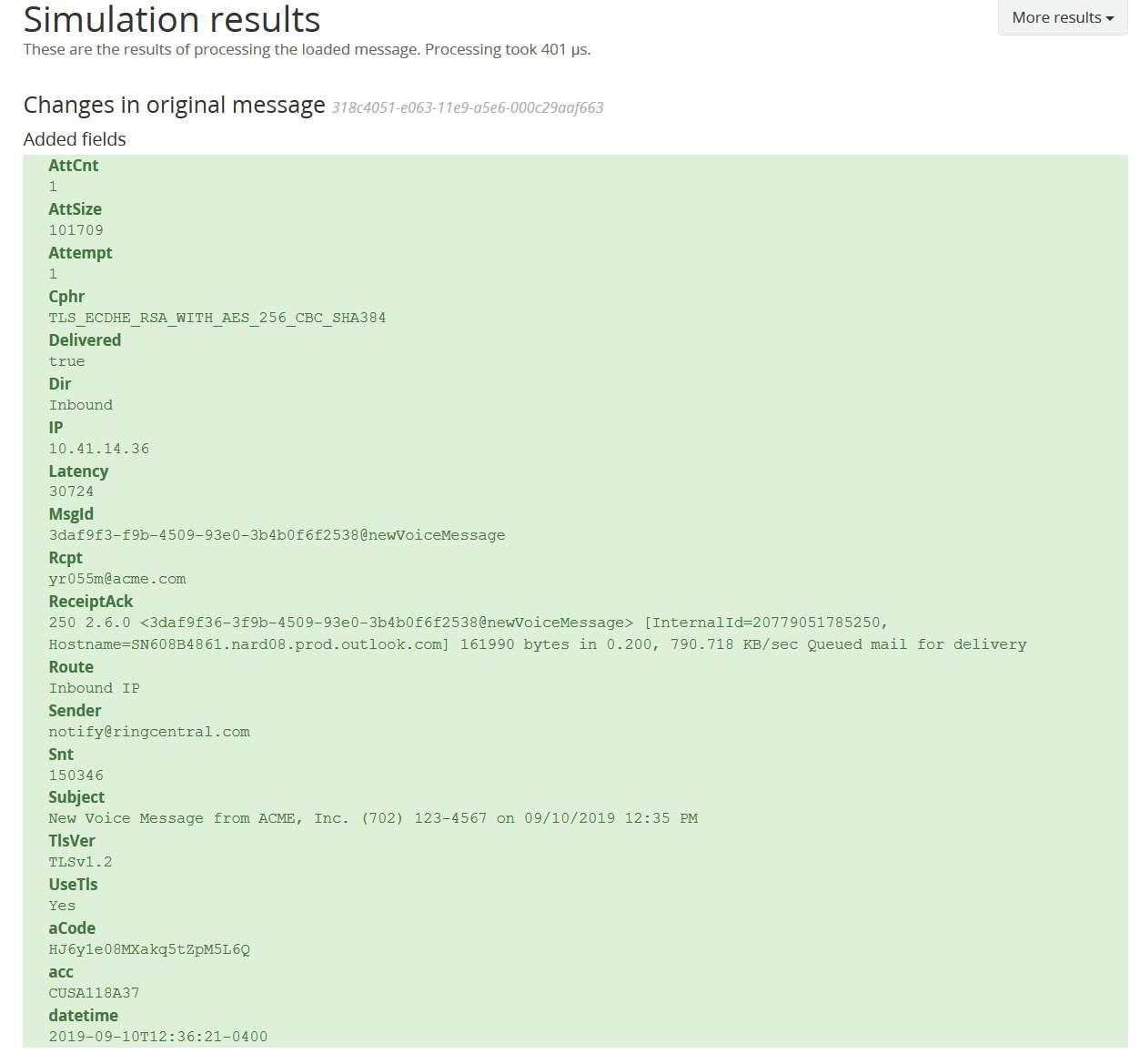
Once you have your results, you can scan through the captured data and identify where you want to do a deeper search. For example, you see a message with a size well over the threshold limit. You can copy and paste the Msg ID into a new search and find more detailed information. You find there are a number of delivery failures. After you’ve determined the cause, you might want to set up an alert to make sure you’ve resolved the issue. Maybe you discover that your latency has gone 100% over the average recorded value, indicating performance issues. In this case, you might want to save your search and chart these values on a Dashboard over the course of the day. This will show you when your latency is highest so that you can identify and fix the performance issues. If you have a list of bad email addresses or known spammers or you have domains with which you should not be communicating, etc. you can set up an alert to monitor this field for violations in policy or security threats, etc.
Key Value Parser and Rules
The way to implement a Key Value parser is through pipeline rules. Pipeline rules are the method Graylog uses to modify data. In the above example, we split a larger block of text, however, you can also use pipeline rules to rename fields, create new fields, delete fields or messages, enrich messages with information like GeoIP, WHOIS, and so on. You can also use rules to look up and compare incoming indicators of compromise against a threat intelligence feed.
For example, you can add the following rule to a pipeline to parse messages formatted using key value pairs.
Rule Text:
rule "key_value_parser"
when
has_field("message")
then
set_fields(
fields:
key_value(
value: to_string($message.message),
trim_value_chars: "",
trim_key_chars: "",
delimiters: "|",
kv_delimiters: "="
)
);
end
Note: the keys and values will not always have quotes around them, but when they do, you define the characters used and tell the pipeline to trim them. That is why the settings “trim key characters” and “trim value characters” in the rule sample below are defined. Those values are left blank if there are no characters to trim.
The parser will take the key as the field name, and the value as the content of that field. That way, you do not have to define field names in your rule, as the message itself contains the field names.
Graylog provides a rule editor so that you can make your rule text easier to read and modify as needed. Here is the rule text from above formatted in the Rules Editor.

Final Thoughts
All of this is the tip of the iceberg of how you can use the Key Value Parser to convert raw machine data into structured data for storage, search, and analysis. It is a powerful method for digging deeply into those large blocks of text to extract meaningful data in a fast and efficient way. You determine what data you want to look for, set up your pipeline rules, add your Key Value Parser, and start working with your data.
