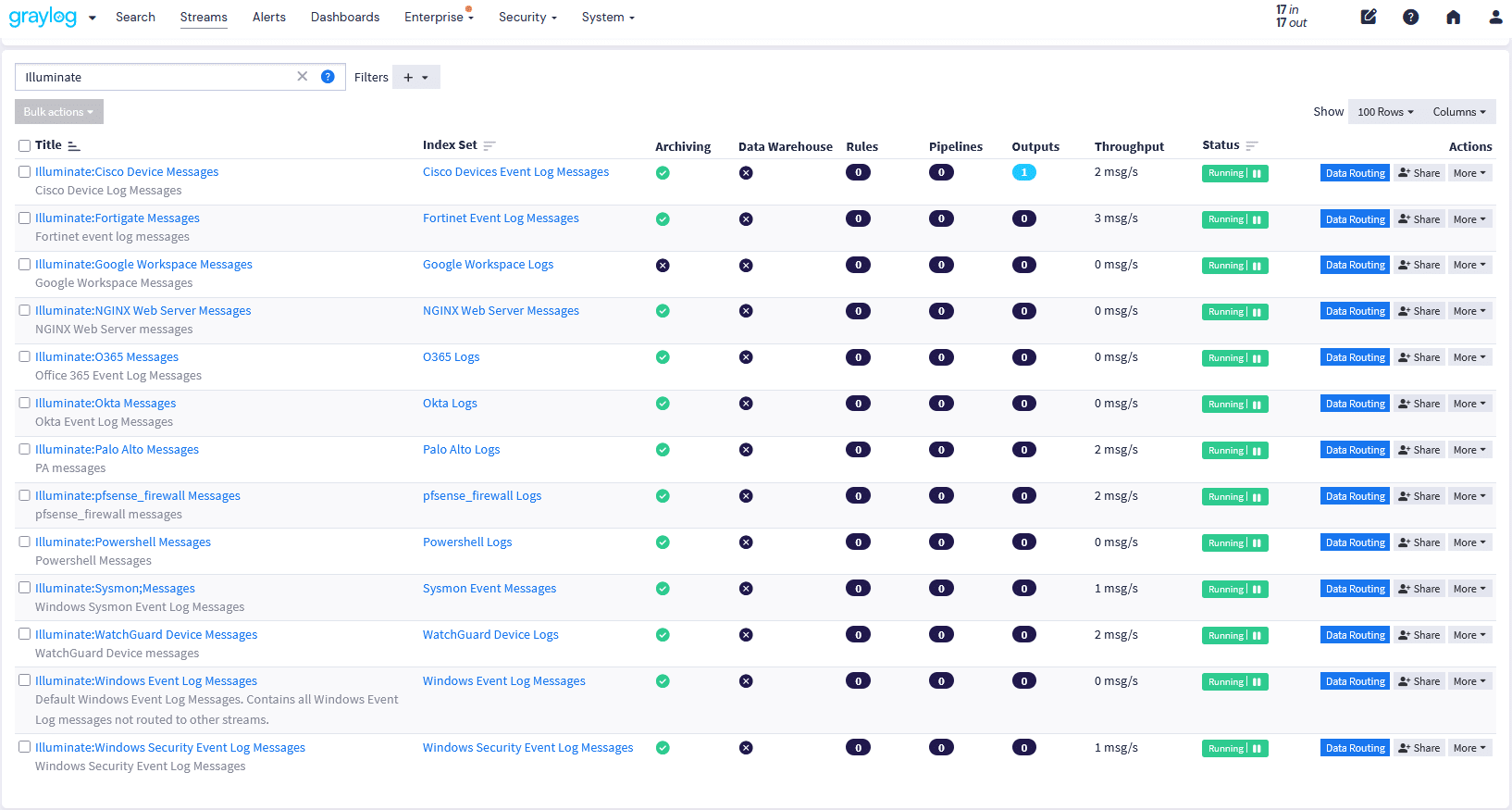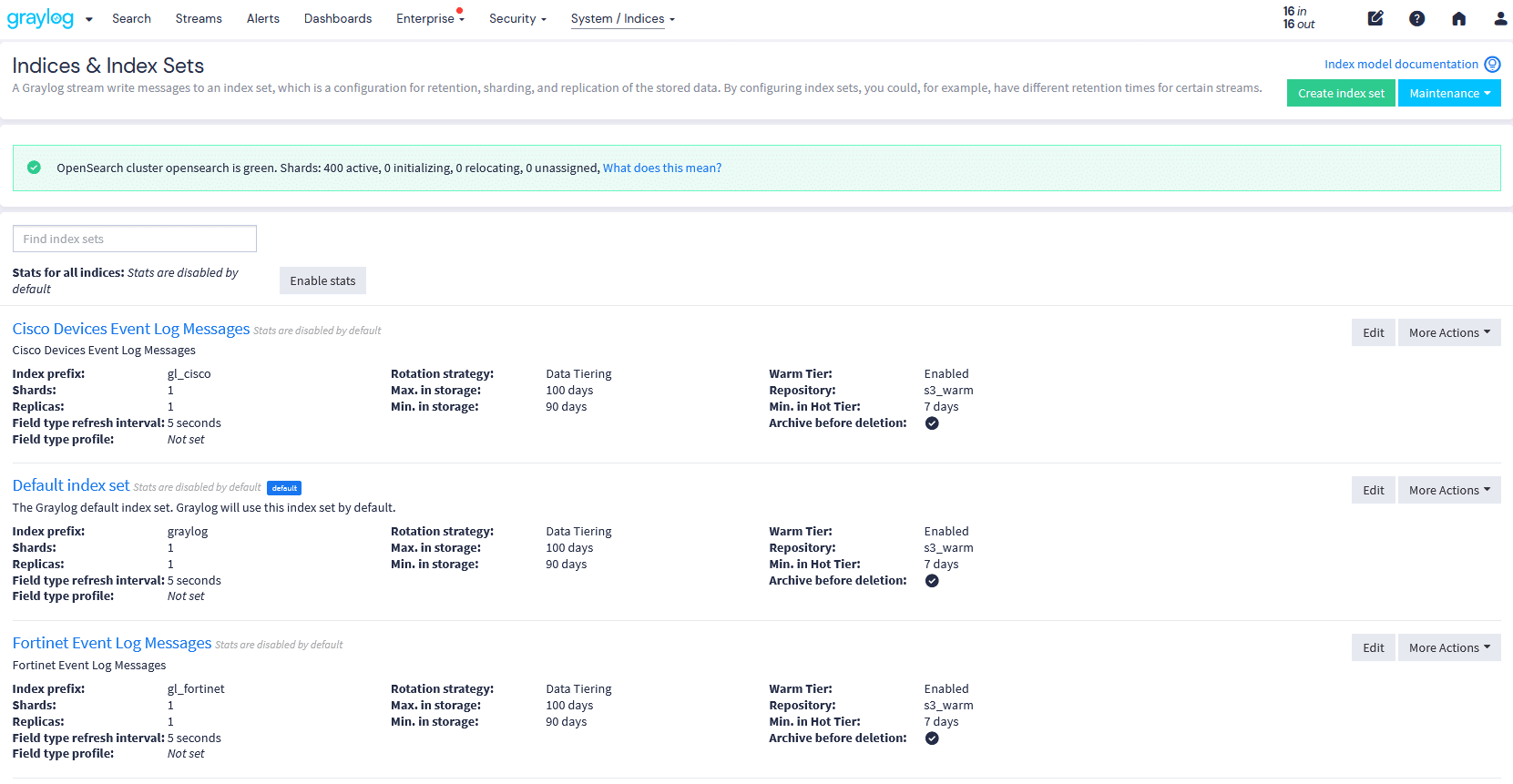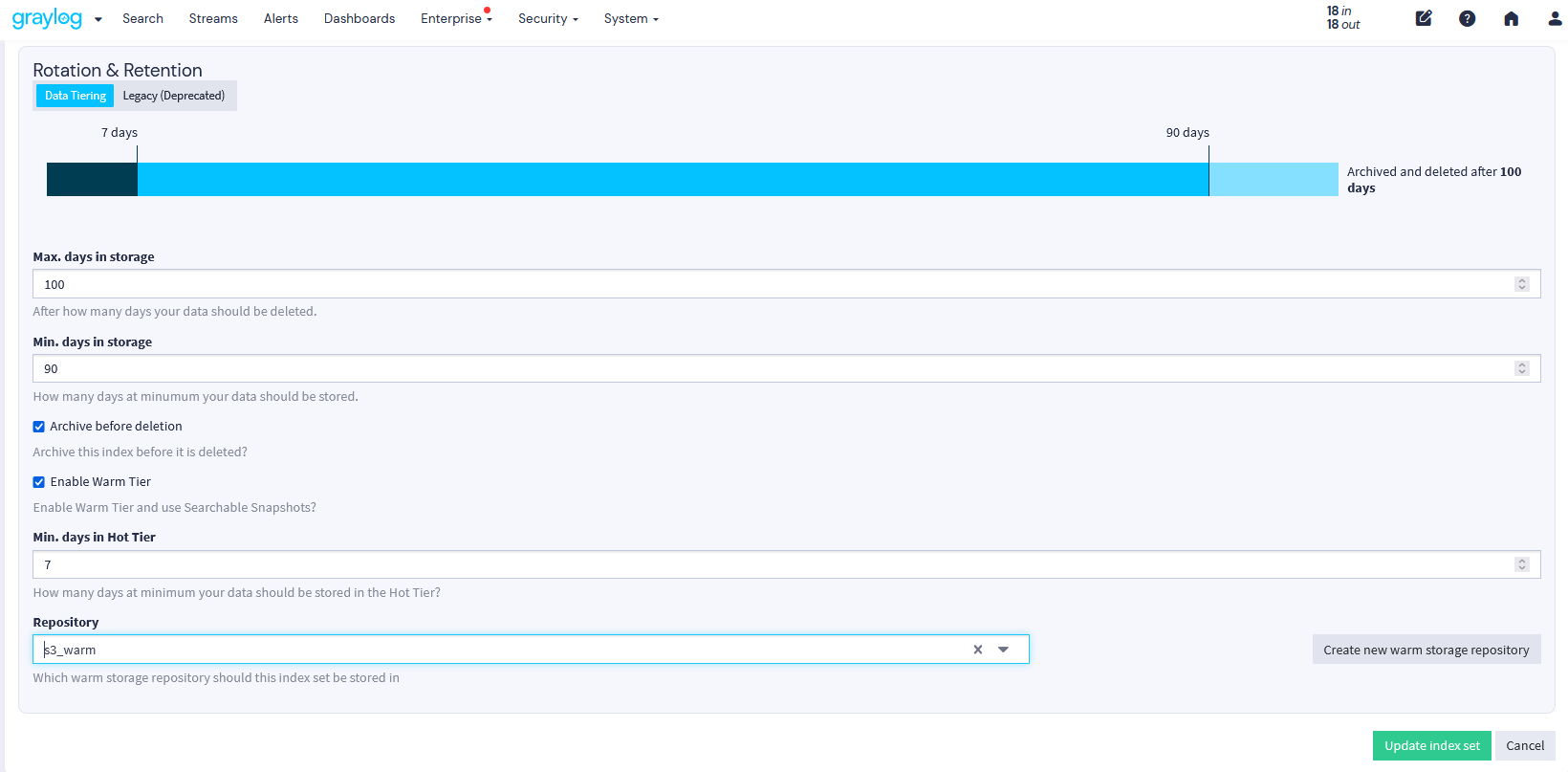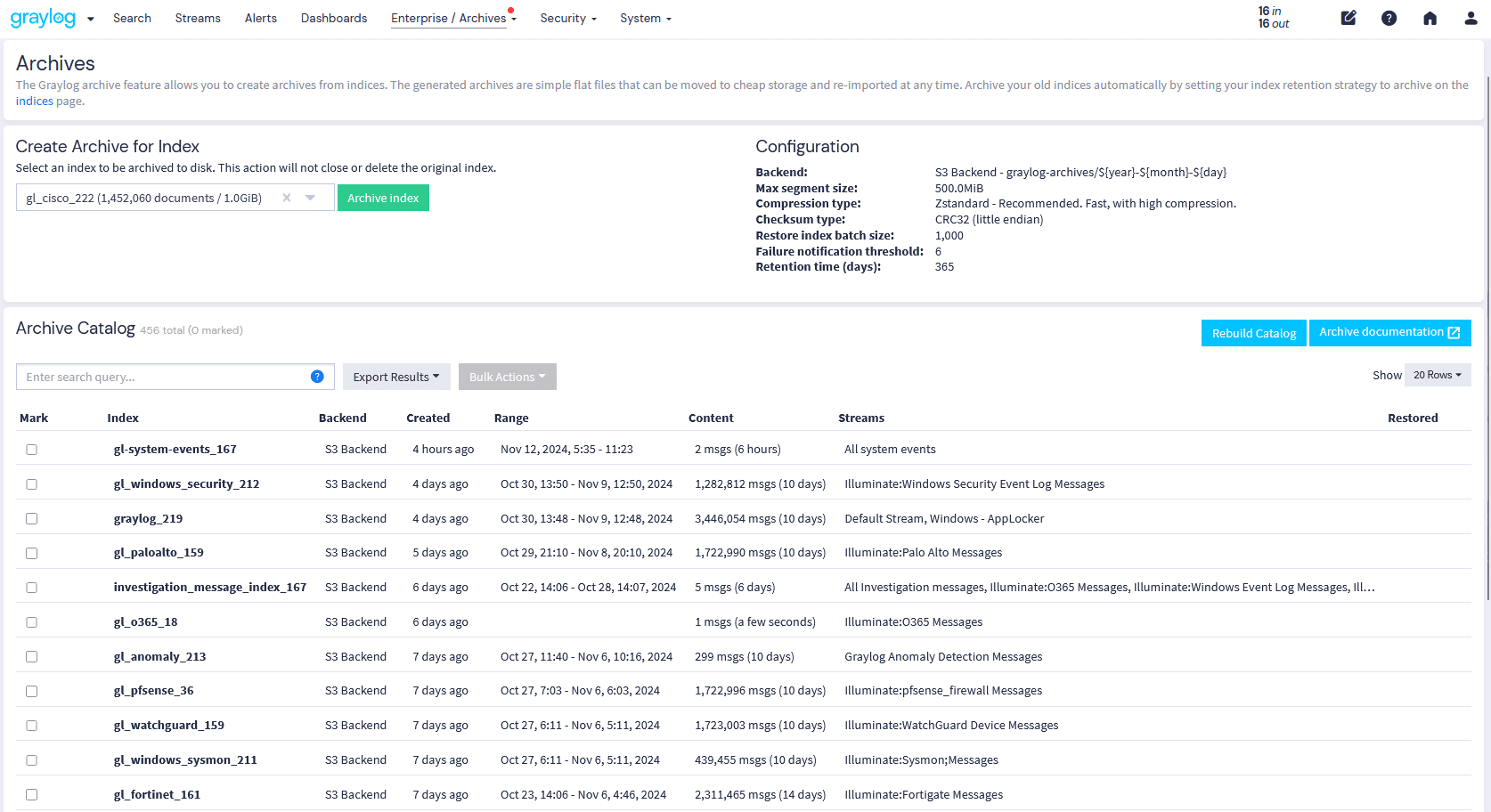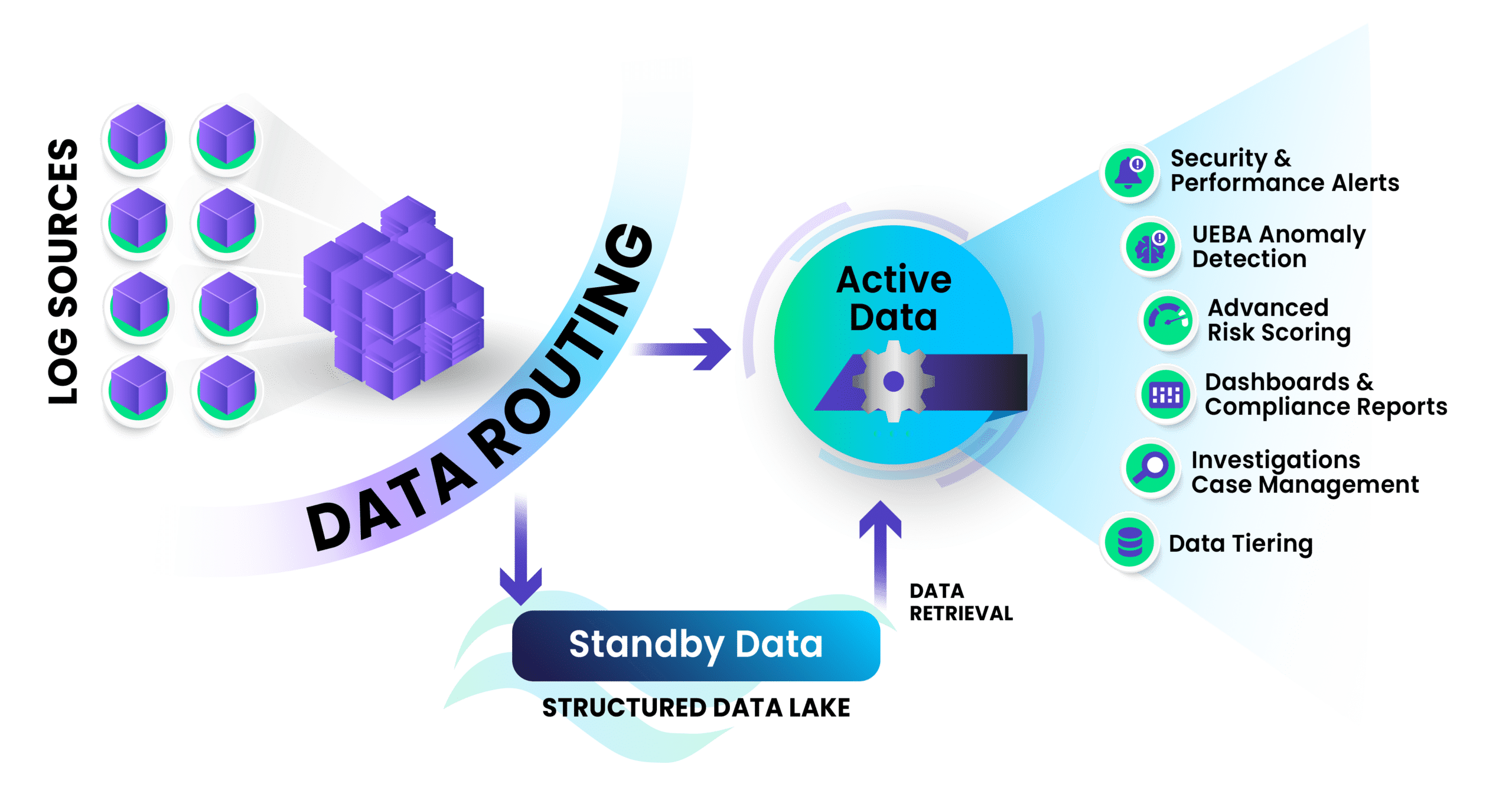
Graylog’s built-in data pipeline management removes reliance on third-party tools, simplifying data handling. Not all logs need immediate processing—some are best stored for future investigations, audits, or forensic analysis and only processed if needed. With Graylog Data Routing, you can send these logs to a Data Lake, Amazon S3, or your preferred network storage solution.
Every organization is different, but some examples of logs that might suited for standby storage include:
- DNS Logs – Useful for retroactive threat hunting or tracking exfiltration attempts but not needed for real-time monitoring.
- NetFlow & PCAP Data – Large-volume network traffic logs that can be analyzed later if an anomaly is detected.
- Verbose Application Logs – Debug or trace logs that may help troubleshoot performance issues but are not needed daily.
- Email Metadata Logs – Records of email flow (sender, recipient, timestamp) that help investigate phishing or data leaks.
- Cloud API Activity Logs – Logs from AWS CloudTrail, Azure Monitor, or other services that track API calls for future security audits.
- Database Query Logs – Captures of complex or bulk queries that may be useful in forensic investigations.
Active data is fully processed in real time for immediate use in dashboards, events, alerts, and anomaly detection. Standby data undergoes light processing and enrichment before being routed to cost-effective storage, ensuring future searchability without impacting license consumption.